Postel's Law and Why Your AI Agents Fight Each Other
Published
The first time I saw an agent crew break on schema drift, four agents were arguing with each other in a Slack thread that no human had asked for.
The orchestrator had upgraded from one model version to the next on Friday afternoon. By Monday morning the planner agent’s output JSON had a new optional field. The executor agent — written by a different team, deployed on a different cadence, never told about the upgrade — saw the unknown field, threw a Pydantic validation error, returned a 500 to the orchestrator, which retried, which got another 500, which fell back to a “supervisor” agent, which logged a structured complaint, which the planner agent then parsed as an instruction and tried to act on.
By the time the on-call engineer caught it, the crew had spent forty minutes generating the most expensive Slack thread in the company’s history and made zero progress on the customer’s actual request.
The narrative in the post-mortem was, predictably, “the agents are too brittle.” That is the wrong diagnosis. The right diagnosis is that we built agent-to-agent APIs that violate the oldest rule we have for systems that have to keep talking to each other across version boundaries.
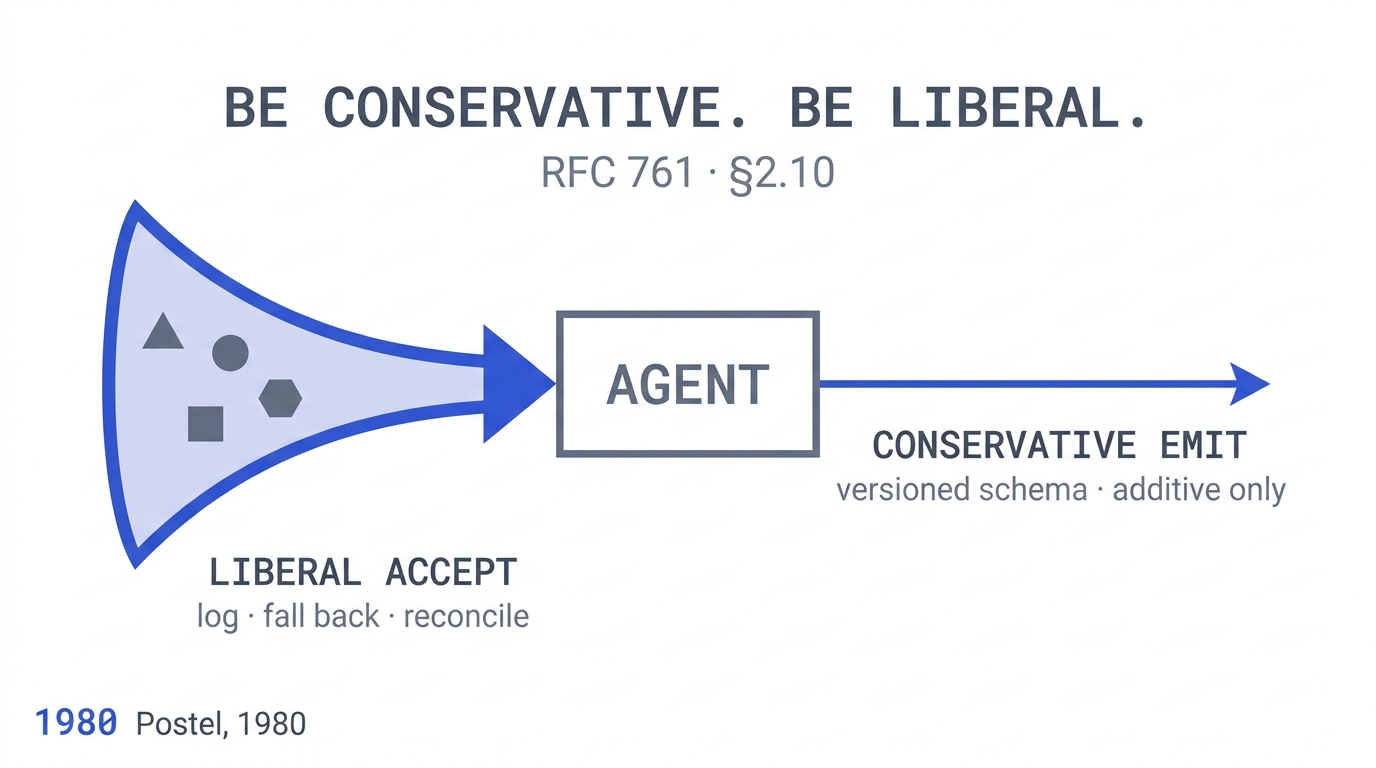
The rule is Postel’s Law, also called the Robustness Principle. Jon Postel formalised it in section 2.10 of RFC 761 in January 1980, when he was specifying TCP for the still-young internet:
“TCP implementations should follow a general principle of robustness: be conservative in what you do, be liberal in what you accept from others.”
For forty-five years that one sentence kept the internet from collapsing every time a new client implementation appeared. It is why the web survived four browser wars. Why TCP-over-anything still works. Why email clients written in 1995 still talk to mail servers shipped last quarter. The implementations on either side of every wire on the internet were never simultaneously upgraded — and the system kept working anyway, because Postel told everyone to write code that did not punish callers for being slightly different than expected. The principle was restated and extended in RFC 1122 (1989) — the foundational Host Requirements standard — to apply at “every layer of the protocols.”
Then we built agent frameworks. And almost every agent-to-agent contract I have audited in the last year does the exact opposite:
- Liberal in what it sends — whatever shape the LLM produced this turn, with whatever optional fields drift in or out across model versions.
- Conservative in what it accepts — one unknown enum value, one missing optional field, one extra key, and the whole call fails.
That is an anti-Postel contract. It is the architecture of a system designed to break on its first version skew. And version skew, in an LLM-driven system, is not a quarterly event. It happens every time a model is upgraded, every time a prompt is tuned, every time a system message is changed. It happens continuously. The contract has to absorb it, or the system stops working.
Key Takeaways
- Multi-agent LLM systems fail at correctness rates between 41% and 86.7% across 7 popular frameworks, with 14 distinct failure modes identified across 1,642 annotated traces (Cemri et al., NeurIPS 2025).
- ~37% of multi-agent failures are inter-agent misalignment — the exact category Postel’s Law was written to prevent (Cemri et al., 2025).
- 57% of companies have AI agents in production (G2 Enterprise AI Agents Report, 2025), but only 24% of developers design APIs with AI agents in mind (Postman State of the API, 2025).
- The 1980 Robustness Principle was restated for the modern era in RFC 9413 (Thomson & Schinazi, 2023) — “for a protocol that is actively maintained, the robustness principle can, and should, be avoided” — under specific conditions every architect should understand.
- The architectural fix is conservative emit, liberal accept with telemetry, and a periodic schema-reconciliation loop. Without the reconciliation loop, liberal acceptance becomes the silent corruption it was meant to prevent.
Why Are Multi-Agent Systems Failing at 41–86.7% Rates?
Cemri and colleagues at UC Berkeley published “Why Do Multi-Agent LLM Systems Fail?” at NeurIPS 2025, the first peer-reviewed taxonomy of failure modes in production multi-agent LLM systems. The headline finding is uncomfortable: across seven popular multi-agent frameworks evaluated on 1,642 annotated traces (with a strong inter-rater agreement of κ = 0.88), task-correctness failure rates ranged from 41% to 86.7% (Cemri et al., 2025).
The breakdown is more uncomfortable still. The authors identified 14 fine-grained failure modes and rolled them up into three categories:
- ~41.8% system design and specification issues — the contract between agents was wrong from the start
- ~37% inter-agent misalignment — the agents disagreed about what the message meant or what state they were in
- ~21.2% task verification failures — nobody downstream caught that the work had not actually been done correctly
The middle category — inter-agent misalignment — is exactly the failure class Postel’s Law was written to prevent. Two implementations talking to each other across a contract boundary, one of them changes, the other does not absorb the change, and the system breaks. Postel solved this for TCP in 1980. The agent ecosystem of 2026 has not yet adopted the equivalent discipline.
The authors then tested the most plausible interventions — prompt engineering plus topology changes on ChatDev — and found correctness improved by only +14%. The conclusion in the paper’s own words is that this remains “insufficiently low for real-world deployment.” Prompt-level patches are not closing the gap. The fix has to be structural.
What Did the Three Failure Modes Actually Look Like?
These are real incidents from the last year, fuzzed for confidentiality. The failure mode in each is exact.
1. The Unknown Enum That Halted the Crew
A multi-agent customer-support system. The router agent’s output schema declared intent: "billing" | "technical" | "account". After a model upgrade, the LLM started occasionally producing intent: "subscription" — semantically a subset of “billing,” but a new string. Every downstream agent had a strict validator. Every call with intent: "subscription" returned a 422.
The framework’s retry policy retried with the same input, got the same 422, escalated to a supervisor, which classified the request as “unprocessable” and routed it to a human queue. The human queue grew by 40% overnight. The on-call engineer who finally caught it spent two hours searching logs for a “system outage” before noticing that every failed message had the same intent string.
The fix was a one-line schema change: accept any string for intent, validate the known values explicitly downstream, log unknowns for review, and route unknowns to a “best-effort” handler rather than a hard 422. Liberal in what you accept. Five minutes of code. Eight hours of incident.
2. The Orchestrator Pass-Through
A research-and-summarise agent emitted a JSON object with a sources array. The summariser downstream consumed it. After a tweak to the research agent’s system prompt, the LLM started emitting a new confidence field on each source — undocumented, unrequested, semantically meaningless to the summariser.
The summariser used a strict Pydantic model with extra = "forbid". Every research output now failed validation. The orchestrator, on receiving the validation error, fell back to a “redo the research” branch. The research agent ran again, emitted the same shape with the same confidence field, failed the same validator, and the loop ran until the framework’s circuit breaker tripped 90 seconds later.
Cost: $14 of LLM spend on a single user query, against a budget assumption of $0.40. Multiply by daily request volume, and the team’s monthly bill came in 6× over forecast. Across a quarter, the integration alone consumed budget the team had earmarked for two new features.
The fix was again one-line: extra = "ignore". Forty-five years of internet history embedded in a single Pydantic config option that was deliberately set the wrong way.
3. The Schema Upgrade Nobody Coordinated
The planner agent and the executor agent were owned by different teams. The planner team shipped a v2 of their output schema, with a renamed field (task_id → task_uuid), in a Friday afternoon deploy. The executor team had not been told. The executor’s strict consumer rejected every v2 message as missing the required task_id.
For two hours, every plan the planner emitted was rejected by every executor in the fleet. The framework’s at-least-once retry semantics turned that into a load spike that the executor team’s pager interpreted as a denial-of-service attempt. There was a brief, embarrassing moment when the executor team blocked the planner’s IP range at the load balancer.
The fix that landed was a real one: a versioned wire schema with an explicit deprecation window. The fix that should have landed earlier was structural: the executor should have accepted both task_id and task_uuid for a transition period, logged a deprecation warning when the old field appeared, and let the migration roll out asynchronously across teams.
That is the Postel pattern. It is not new. It is how every long-lived API on the internet has handled field rename for thirty years.
What Does the Principle Look Like in Agent Terms?
Postel’s Law in 1980 was a rule about TCP implementations. The agent-to-agent translation is the same shape with different nouns:
- Conservative in what you emit. The agent’s output schema is documented, stable, versioned. New fields are additive. Removed fields go through a deprecation window. Field semantics do not change silently across model upgrades.
- Liberal in what you accept. The agent’s input parser accepts unknown fields without erroring, accepts unknown enum values with a documented fallback, accepts missing optional fields with a documented default, and logs every divergence for review.
These two rules together produce a system where any one agent can be upgraded, retrained, or replaced without taking the rest of the crew down. Without them, the entire crew is a single deployment unit, and every team has to coordinate every release on a shared maintenance window. That is the failure mode of every distributed system that ignored Postel — and it is the failure mode showing up in the Cemri taxonomy as “inter-agent misalignment,” at 37% of all observed multi-agent failures (Cemri et al., 2025).
How Does This Connect to API Design Maturity in 2026?
The data on API design maturity is unflattering. Postman’s 2025 State of the API report, based on a survey of more than 5,000 developers, found that only 24% of developers actively design APIs with AI agents in mind — even though 89% use generative AI in their daily work (Postman, 2025). The report also found that 93% of teams report blockers like duplicated work, poor discovery, and outdated context, with 39% citing inconsistent documentation as the biggest roadblock (Postman, 2025).
This is the gap between adoption and maturity.
The result is the situation Cemri’s taxonomy documents. Production multi-agent systems are being deployed against APIs that were not designed for non-deterministic emitters, and the failure rate reflects the design mismatch.
What Is the Honest Counter-Argument? RFC 9413, 2023.
I cannot write about Postel’s Law without engaging the modern critique honestly. Martin Thomson and David Schinazi’s RFC 9413 — Maintaining Robust Protocols, published by the Internet Architecture Board in 2023 — is the IETF’s own restatement of when Postel’s principle should and should not apply (Thomson & Schinazi, RFC 9413, 2023).
Their argument, simplified: when receivers are too liberal in what they accept, senders learn that they can emit malformed output with no consequence. Over time, the malformed output becomes load-bearing — and the receiver can no longer tighten the contract without breaking everyone. The principle, applied without discipline, creates the brittleness it was meant to prevent. Their headline conclusion is unambiguous: “for a protocol that is actively maintained, the robustness principle can, and should, be avoided” (RFC 9413, 2023).
This is exactly what happens in agent systems if you stop at “set Pydantic to ignore extra fields.” The unknown confidence field from the research agent in failure mode #2 becomes a de-facto API. Some downstream agent eventually starts depending on it. The research-agent team tries to remove it six months later. The dependent agent breaks. Now the field is permanent and undocumented. That is the silent-corruption failure mode RFC 9413 warns about.
The discipline that closes the gap is explicit logging plus periodic schema reconciliation. Liberal acceptance is a runtime property. Every divergence — every unknown field, every unknown enum — is logged with the caller, the operation, and a timestamp. The team reviews the divergence log on a cadence (weekly is enough for most systems) and either:
- Promotes a divergence to a documented schema field, or
- Issues a deprecation notice to the upstream agent’s owner.
Without that loop, Postel becomes the silent-corruption failure mode RFC 9413 warned about. With it, you get the resilience of a system that survives version skew without the entropy of a system whose schema is whatever the LLM happened to emit last Tuesday.
The 2023 IETF position is not “abandon Postel.” It is “Postel without discipline becomes Postel without a schema.” The discipline is the schema-reconciliation loop. That is the modern reading.
Can’t Structured Outputs Just Solve This?
Constrained-decoding APIs (OpenAI Structured Outputs, Anthropic Tool Use, Gemini Response Schema) reduce the emit-shape failure rate dramatically — from prompt-only JSON extraction failing 5–20% in production, to OpenAI JSON Mode at 2–5%, to constrained decoding at under 0.3% (cross-provider analysis, 2025).
That is a real engineering improvement. It does not, however, solve the Postel problem.
Two reasons. First, JSONSchemaBench — a January 2025 benchmark of 10,000 real-world JSON schemas — found roughly 2× variance in schema coverage between the best and worst constrained-decoding frameworks (Geng et al., 2025). The schema you specified is not necessarily the schema your provider’s constrained decoder fully supports. Edge cases leak through. Second, even when the emit-shape is locked down, the semantic content of the emit can still drift across model versions. The shape is {intent: string}. The string was “billing” yesterday and is “subscription” today. Constrained decoding does not catch that. Postel does.
The structured-output APIs are the conservative-emit half of the principle, automated. They do not substitute for the liberal-accept half. Both halves have to be present.
What Does the Architectural Fix Actually Look Like?
Three rules I am asking every agent platform team to adopt. They are not new. Restated for agents from the way long-lived web APIs have handled this since the 2000s.
Rule 1 — Conservative emit, by default. Every agent’s output schema is versioned, documented, and tested. The agent’s framework refuses to emit fields not in the schema. New fields ship through a versioned release, not a prompt tweak. Use constrained decoding (OpenAI Structured Outputs, Anthropic Tool Use, equivalent) where supported. Where a field rename is unavoidable, run a deprecation window — Stripe’s API versioning policy is the canonical reference for how to do this in production at scale (Stripe API Versioning, 2024).
Rule 2 — Liberal accept, with telemetry. Every agent’s input parser tolerates unknown fields and unknown enum values, logs the divergence with structured metadata, and routes unknowns through a documented fallback path — never a 422. Pydantic extra = "ignore" is the minimum. The maximum is a typed parser that records every divergence to a queryable store with the schema version that produced it.
Rule 3 — Reconcile the divergence log. A weekly review converts logged divergences into either schema additions or upstream deprecations. The log does not grow forever. The schema absorbs reality. This is the rule that closes the RFC 9413 critique. Without it, Rule 2 produces undocumented load-bearing fields. With it, Rule 2 produces a schema that converges on what the system actually emits.
Three rules. They sound like internet engineering from 2005. That is because they are.
The deeper observation is that the agent frameworks have not yet shipped these rules as defaults. The framework that does — that ships an “agent-to-agent contract layer” with conservative emit, liberal accept, and reconciliation telemetry built in — will become the default platform for production multi-agent systems within 18 months. The pattern repeats every time a substrate matures. RPC went through it. SOAP went through it. REST went through it. Webhooks went through it. The agent ecosystem is going through it now. The framework that makes the safe path the easy path wins.
Frequently Asked Questions
Why is “be liberal in what you accept” controversial in 2026?
The IAB’s RFC 9413 (Thomson & Schinazi, 2023) argues that liberal acceptance creates load-bearing undocumented behaviour over time, making protocols harder to evolve. The critique is correct in actively maintained protocols with strict versioning. It does not eliminate the principle — it specifies the discipline (logging, reconciliation, versioning) required to apply it safely.
Don’t structured outputs from OpenAI and Anthropic solve this?
They solve the emit-shape half of the problem. JSONSchemaBench found roughly 2× variance in schema coverage between leading frameworks (Geng et al., 2025), and structured outputs cannot detect when an enum value drifts from “billing” to “subscription” across model versions. Constrained decoding is the conservative-emit half of Postel’s Law, automated. The liberal-accept half still requires the receiver to be tolerant.
How is this different from regular API versioning?
Regular API versioning assumes deterministic emitters. LLMs are non-deterministic. The output shape can drift between requests against the same API version, and the semantics of enum values can shift across model upgrades without any schema change at all. Postel’s discipline plus reconciliation telemetry is what closes the gap that traditional versioning leaves open.
What is the minimum viable adoption?
Set extra = "ignore" (or your stack’s equivalent) on every agent input parser, log every unknown field to a structured store with caller and timestamp, and review the log weekly. That single workflow closes the inter-agent misalignment failure mode that accounts for 37% of all multi-agent failures in the Cemri taxonomy (Cemri et al., 2025).
Does this scale to many agents?
Yes — better than the alternative. The cost of the reconciliation review grows linearly with the number of contract boundaries, not the number of agents. A 20-agent system with 10 named contracts has the same review cost as a 5-agent system with 10 named contracts. The cost grows with contract surface, which architects can control directly. Without Postel’s discipline, the cost grows with the deployment-coordination complexity, which scales factorially.
What Is the Closing Argument?
The agent ecosystem is rediscovering the lessons every distributed-systems substrate before it has had to learn the hard way. RPC learned it. SOAP learned it. REST learned it. Webhook delivery learned it. Each generation produced its own folklore, and most of that folklore reduces to one line written by Jon Postel in 1980.
Be conservative in what you emit. Be liberal in what you accept. Then write down the divergences you accepted, so the schema absorbs reality on your terms, not the LLM’s.
Most of the agent failure narratives I am asked to debug — “the crew lost track,” “the agents fought each other,” “the orchestrator went into a loop” — disappear under that one rule, applied with the discipline RFC 9413’s modern restatement demanded.
The internet survived its own version-skew problem by writing exactly this rule onto a TCP RFC and holding the line for forty-five years. The agents we are building today will only survive the same problem if we remember why the rule was written in the first place.
It was written because every long-lived system that talks to other systems will eventually face a version it did not expect.
Including yours. Including next week.
This article is part of a four-week series connecting old software-engineering principles to new AI failure modes. Companion piece on idempotency and at-least-once delivery: Why Every AI Agent Failure I’ve Debugged in 2026 Was an Idempotency Problem.