Graduated Enforcement: From Monitor to Hard Enforce Without Breaking Production
Published
Phase 3 is where most Zero Trust programmes die. The controls are built. The policies are written. Someone flips enforcement on across the board, a legitimate service-to-service call gets blocked, a revenue-path incident ensues, and by Friday the team has retreated to “permissive mode” and quietly stopped talking about segmentation. Illumio’s 2024 field data shows graduated rollout cuts segmentation-related outages by ~40% versus manual cut-over — which is another way of saying the 40% of programmes that skip graduation are the ones that break things.
This is Phase 3, Chapter 1 of the 90-Day Zero Trust Playbook. The design work from P6 Micro-Segmentation Design and the baseline from P5 Network Baselining feed this chapter. The deliverable is enforcement in production without an incident.
Key Takeaways
- Graduated enforcement cut segmentation outages by ~40% vs. manual cut-over in Illumio’s 2024 customer study (Illumio)
- Agent-based enforcement rollouts take 3–6 months; agentless cloud-native rollouts can finish in weeks — plan timelines to the tool, not to the calendar (SentinelOne)
- Real-world coverage maxes around 60% of apps by count even in mature programmes (Elisity) — enforce the T0/T1 60% first; the tail can stay in monitor mode indefinitely
- Pre-staged rollback scripts with a 15-minute recovery target are the cheapest insurance you can buy — FireMon’s rollout guidance treats rollback as a first-class design concern, not an afterthought
- Canary groups sequence as IT team → one business unit → whole company. Skipping the BU step is how enterprise rollouts turn into enterprise incidents
The Anti-Pattern First
Name it so you can avoid it. The anti-pattern has five moves: (1) deploy enforcement to everything simultaneously, (2) block legitimate traffic nobody documented, (3) field a P1 incident during a revenue-critical window, (4) roll back to permissive under pressure, (5) declare segmentation “not ready yet” and let the programme quietly stall. Every one of these is preventable by staging.
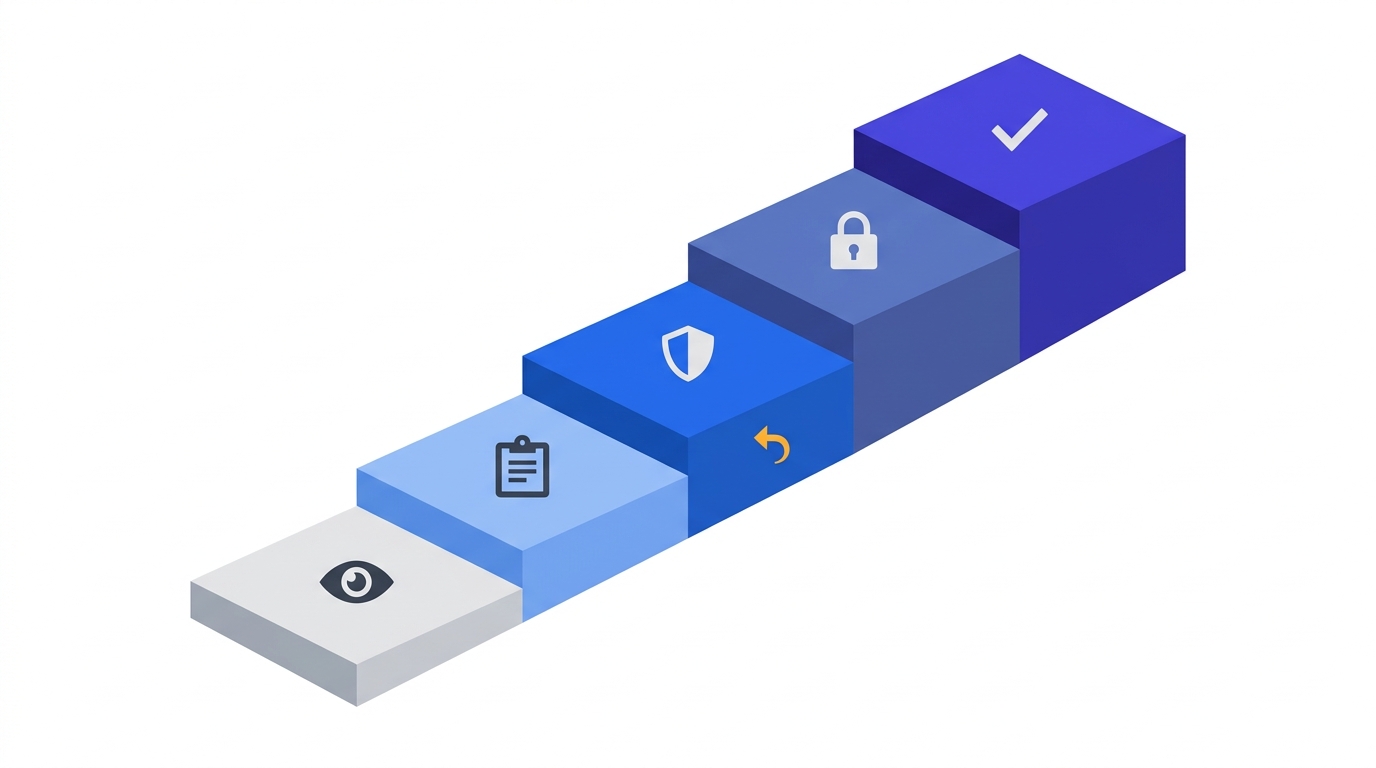
The Five-Step Graduation
Each step has a clear success criterion and a rollback trigger. Do not proceed to the next step until the current one has been stable for the minimum dwell time.
Step 1 — Monitor. Already running since P5 baselining. Policy is defined but traffic flows freely. You are watching for surprise dependencies and violations the design missed. Dwell: continuous, overlapping with the next step.
Step 2 — Soft enforce (log, don’t block). Turn the policy on in audit/permissive mode: Istio PERMISSIVE, Illumio Visualisation, NSX Idle, Cilium Audit. Every would-be block generates a log entry. No traffic is actually blocked. Dwell: one week minimum, four weeks for T0 systems. Success: 48 hours with zero unexplained would-be-blocks on T0/T1 flows.
Step 3 — Hard enforce (segment by segment). Block. But one segment at a time, starting with the segment you understand best — not the legacy ERP. Use the Business Impact × Technical Feasibility ranking from the Application Criticality Scorecard. Dwell: 48 hours of stability per segment before moving to the next. Success: no P1/P2 incidents attributable to policy for 48 hours; helpdesk volume within 2× baseline.
Step 4 — Validate. After each segment hardens, actively verify: run synthetic transactions through the protected flows, check that dashboards reflect the enforced state, confirm exceptions (if any) were pre-approved and tagged. Dwell: 24 hours. Success: validation checklist complete, steering committee signed off.
Step 5 — Expand. Next segment. Repeat Steps 3 and 4. Never more than two segments in active enforcement-transition at the same time — the blast radius of a misconfigured policy compounds.
Rollback Triggers (Non-Negotiable)
Define rollback triggers before you start, not during an incident. The three that should be pre-written into the runbook:
- Tier 1 application outage — immediate rollback. No pager debate.
- Helpdesk volume at 3× baseline for more than an hour — pause enforcement, triage, resume only after root cause is known.
- Revenue-path impact (order flow, payment, core-product availability) — immediate rollback, blameless post-mortem mandatory.
Pre-stage the rollback scripts and test them in a non-production segment before the first production enforcement. Target: 15-minute recovery from trigger to restored traffic. FireMon’s rollout guidance puts rollback rehearsals on the same tier as the segmentation design itself — if the rollback isn’t rehearsed, the enforcement isn’t ready.
Canary Group Strategy
Ship to humans the way you’d ship to machines: in concentric rings.
- Ring 0 — the IT team itself. The team that wrote the policy is the first to live under it. Dwell: one week. If the people who understand the policy can’t survive enforcement, nobody can.
- Ring 1 — one business unit. Pick a unit that is technical-tolerant but revenue-material — engineering ops, platform teams. Not the sales-close-week team. Dwell: two weeks.
- Ring 2 — the rest of the company, by BU, staged. Never a big-bang flip from one BU to all BUs.
Skipping Ring 1 is the most common mistake. It feels like bureaucracy after Ring 0 passed; it is actually how you find the category of problem that only appears at BU scale.
Timeline Reality
SentinelOne’s field data and practitioner write-ups converge on two very different clocks:
- Agent-based enforcement (Illumio, Guardicore, host-based) — 3–6 months from Step 2 to full Step 5 coverage of T0/T1 in a typical mid-market estate. Agent deployment, compatibility testing, and policy-per-host dominate the timeline.
- Agentless / cloud-native (security groups, service mesh, eBPF) — weeks for the equivalent scope. Policy lives in infrastructure-as-code and deploys at the speed of your existing change-management process.
Align the Phase 3 timeline to the tool. Do not promise the board a 30-day enforcement if you’re running an agent-based rollout.
The federal evidence backs the same clock. The NSA’s January 2026 Zero Trust Implementation Guideline Primer describes its Phase Two — the phase that “marks the beginning of integrating distinct ZT fundamental solutions” — as 41 activities supporting 34 capabilities. That is the federal-equivalent scope of the work this chapter covers. If a fully resourced DoW programme treats it as a multi-quarter undertaking, your mid-market enterprise should not be promising it in a sprint.
Communication Template
Every enforcement wave needs the same one-page brief, sent before the change window:
- What’s changing — one sentence, non-technical.
- When — date, time, expected duration.
- What users should do — usually nothing, but name it explicitly.
- What happens if you are blocked — the self-service remediation link from the Device Trust & BYOD tiering work.
- Who to contact — exactly one channel, staffed during the window.
Ship this before the change, not during the incident. The difference between a controlled rollout and a crisis is usually not the technology; it is whether people knew what was happening.
What You Hand to Operations
By the end of this chapter, you should have:
- Enforcement live on T0/T1 application segments, validated and signed off
- Rollback runbooks rehearsed in a non-production segment, 15-minute recovery target confirmed
- Canary ring plan documented and followed for every new segment
- Weekly exception and violation review integrated into the steering committee
- A tail of T2/T3 workloads that stays in monitor mode indefinitely — that is a deliberate decision, not a failure
Continue to CI/CD Pipeline Hardening for the supply-chain half of Phase 3, or return to the 90-Day Playbook hub for the cross-cutting operations chapters.