Why Every AI Agent Failure I've Debugged in 2026 Was an Idempotency Problem
Published
The failure pattern looks different every time, and it is the same pattern every time.
A customer gets the same onboarding email fourteen times in nine minutes. A B2B account is charged twice for one subscription renewal. An order shows up in the OMS as three orders, two of them for products the customer did not select. A support ticket is created, escalated, re-created, re-escalated, and then closed as duplicate by a human who eventually has to write the apology email.
Every one of these incidents in the last six months has landed on my desk with the same opening line in the post-mortem: “the agent acted weirdly.”
The agent did not act weirdly. The agent did exactly what the framework told it to do — retry on timeout, retry on 5xx, retry on ambiguous tool response — against a tool call that was never designed to be retried. That is not an AI failure. That is a 25-year-old distributed-systems failure wearing a new costume.
The principle the agent ecosystem is currently rediscovering is idempotency: an operation is idempotent if applying it once and applying it more than once produce the same result. Roy Fielding formalized the property for HTTP methods in chapter 5 of his 2000 REST dissertation (Fielding, Architectural Styles and the Design of Network-based Software Architectures, UC Irvine, 2000). The folklore is older — RPC implementers were debating it in the 1980s, and the HTTP/1.1 specification co-authored by Fielding made it normative in RFC 2616 §9.1.2 (later restated in RFC 7231 §4.2.2).
By 2010, idempotency was a non-negotiable in any serious payments, messaging, or inventory system. The agent frameworks of 2024–2026 ship with retry semantics at the tool-call layer. The tools they call were written by humans, for humans, on the assumption that a human would not press the button fourteen times in nine minutes. The collision between those two assumptions is where the production damage lives.
Key Takeaways
- Tool calls now appear in 21.9% of agent traces, up from 0.5% in 2023 — a 44× expansion of the retry surface in a single year (LangChain State of AI 2024, 2024).
- 40% of enterprise applications will feature task-specific AI agents by end of 2026, up from less than 5% in 2025 (Gartner, 2025).
- Gartner forecasts over 40% of agentic AI projects will be cancelled by end of 2027 — governance, ROI, and reliability gaps drive the failures (Gartner, 2025).
- Every major delivery substrate the agent ecosystem inherits is at-least-once: Stripe retries webhooks for 3 days, AWS SQS standard queues document duplicate delivery as a guarantee, and HTTP retries are normative.
- The architectural fix is unchanged from 2017: every state-mutating tool requires a deterministic idempotency key plus a deduplication store at the boundary. Frameworks do not enforce this by default.
Why Is This Happening Now? Because the Retry Surface Just Got 44× Bigger
Tool calls appeared in 21.9% of agent traces in 2024, up from 0.5% in 2023, with the average agent trace running 7.7 steps end-to-end versus 2.8 the year prior (LangChain State of AI 2024, 2024). Each step is a potential non-idempotent side effect. The retry surface area of the average agent system grew by roughly 44× in a single year, and the tools on the receiving end of those retries did not.
The architectural shape of an agent system in 2026 looks like this. A user request enters the system. An LLM call produces a tool invocation. A framework dispatches the tool. The tool calls a downstream service. The downstream service may itself dispatch a webhook. Every one of those hops is a place where a network timeout, a 5xx response, or an ambiguous result can trigger a retry — and most of those retries happen automatically without the agent author opting in.
This is not new behaviour at the network layer. What is new is the volume of state-mutating calls being generated by a non-deterministic upstream component. An LLM that produces “approximately the right tool call” 95% of the time also produces “almost-but-not-quite the same tool call” the other 5% — and 5% of millions of calls a day is enough to expose every non-idempotent operation in the entire downstream stack.
The LangChain telemetry is consistent with what I see across agent platforms in 2026: more tool calls, longer traces, and a growing population of teams shipping agents into production without a coherent answer to “what happens when this exact call is made twice?”
51% of survey respondents in the LangChain State of AI Agents Report (2024) reported running agents in production. 89% of organisations in the State of Agent Engineering 2025 report have observability or tracing implemented. The instrumentation is catching up. The contracts at the tool boundary are not.
What Did the Five Production Failures Actually Look Like?
These are real incidents from the last six months. Names and details are fuzzed; the failure mode is exact.
1. The Fourteen-Email Onboarding
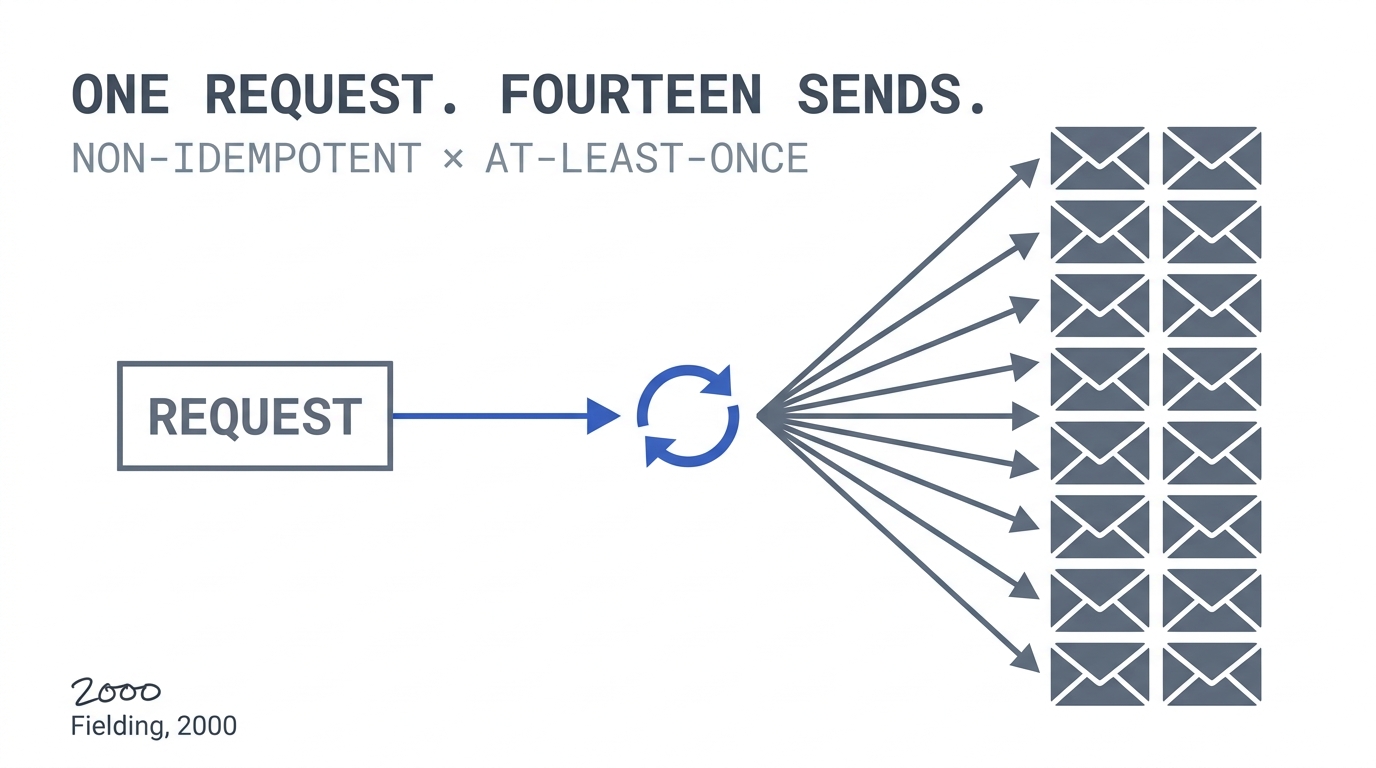
A B2C signup flow runs an agent that, after account creation, calls a send_welcome_email tool. The tool wraps an internal email-service API. The internal API is eventually consistent — it returns 202 Accepted before the message is enqueued, and under load occasionally returns a socket timeout after the message was enqueued. The agent framework’s default policy: retry on timeout up to three times with exponential backoff. The tool itself: no idempotency key, no de-duplication.
Result on a bad afternoon: the agent retried the call three times against a service that had successfully accepted the request the first time. Then the customer support agent — also driven by the framework — saw the customer had not “completed onboarding” (a flag set elsewhere) and re-ran the welcome flow. Three retries × four sequential retriggers = fourteen emails to one mailbox.
Cost: one enterprise customer publicly tweeted about the behaviour. Two hours of incident response. A week of churn-control outreach.
2. The Double Subscription Charge
A self-serve renewal flow uses an agent to handle decline-and-retry on subscription billing. The Stripe call was idempotent — Stripe’s API has supported Idempotency-Key headers for years, with a documented 24-hour window in which retried requests with the same key return the original response rather than re-executing (Stripe API Reference, 2024). The internal entitlement-grant call after the charge succeeded was not idempotent. It posted to a service that wrote a row to a “subscription_grant” table on every call.
When the agent’s first Stripe call returned a network-layer error after Stripe had already charged the card, the agent retried the whole sequence — including a second successful Stripe charge (because the framework’s retry was at the agent step, not the tool step) and a second entitlement grant.
The customer was charged twice. The entitlement table had two grants. Reconciliation took the finance team a full week and the refund cost the team trust they had taken nine months to build.
The lesson here is uncomfortable: Stripe’s idempotency layer was correct, and the system still produced a duplicate charge, because the retry was orchestrated one level above where the idempotency key lived. Idempotency is not a property of one call. It is a property of every layer in the call chain.
3. The Ghost Order
An order-capture agent calls an OMS create_order tool. The OMS expects a client-supplied order ID and is in fact idempotent on that ID — but the agent, on retry, generated a new UUID for each attempt because the prompt said “generate an order ID” rather than “reuse the order ID across retries.”
The retry semantics were correct at the framework layer. The tool was correct at the OMS layer. The instruction set sat between them and broke the chain. Every retry created a new order ID, which created a new order, which the warehouse system happily picked, packed, and shipped.
This is the most insidious of the five, because every individual layer was idempotent-aware. The integration was not. The non-determinism of the LLM produced new IDs on retry, defeating the very property the OMS had been designed to provide.
4. The Webhook Fan-Out
A vendor’s webhook delivery includes at-least-once semantics — they retry on any non-2xx response within 30 seconds. This is not an unusual configuration. Stripe’s published webhook retry schedule extends retries across immediate, 5-minute, 30-minute, 2-hour, 5-hour, 10-hour, and then every-12-hour windows for up to 3 days (Stripe Webhooks Best Practices, 2024). Duplicate delivery is the documented expectation, not the edge case.
The receiving agent, on first delivery, called an adjust_inventory tool that decremented stock levels. The tool’s response shape included a debug field that triggered a Pydantic validation error in the framework’s parsing layer, returning a 500 to the webhook source.
The vendor retried. The framework parsed correctly the second time. Inventory was decremented twice. By the time the on-call SRE caught the divergence, three of the SKUs were oversold and the next sync to the e-commerce frontend had already pushed the wrong stock counts to production.
The fix was not in the agent. The fix was in the inventory tool, which should have accepted an idempotency key from the webhook source and rejected duplicates with a 200, not re-executed.
5. The Duplicate Jira
An incident-triage agent ingests a support email and creates a Jira ticket via a create_issue tool. The first call succeeded. The framework’s response timeout was misconfigured — set to 8 seconds against a Jira instance that, under load, regularly took 12. The agent retried. Jira created a second ticket. The triage agent then ran its own dedup pass, looked at both tickets, and merged them — but the merge step ran another tool call, which timed out, retried, and produced a third ticket.
By the end of the morning, one customer email had produced six Jira tickets, two Slack threads, and a lurid graph in the metrics dashboard nobody could explain.
What Is the Underlying Pattern, Stated Clearly?
In every one of these cases, the surface narrative was the agent’s behaviour. The actual cause was an operation that was non-idempotent in the path of an at-least-once delivery semantic. Non-idempotent operation. At-least-once delivery semantic. If those two facts are true at the same boundary, you do not have an AI failure. You have a distributed-systems failure that AI made cheaper to trigger.
The agent did not invent the retry. The agent did not invent the network timeout. The agent inherited an at-least-once world from every layer beneath it — the LLM provider’s retry on rate-limit, the framework’s retry on tool error, the SDK’s retry on socket close, the webhook source’s retry policy, the queue’s redelivery contract — and pointed it at tools that were originally designed for a single human caller pressing a single button once.
Why Are At-Least-Once Semantics Inescapable?
Every major delivery substrate the agent ecosystem inherits is at-least-once. This is not a pessimistic framing. This is the documented behaviour of the systems your agents are calling.
AWS SQS standard queues document at-least-once delivery as a guarantee, with duplicate delivery treated as the contract not the exception (AWS SQS Developer Guide, 2024). Apache Kafka defaults to at-least-once with exactly-once available only via opt-in transactional configuration. HTTP retries are normative — RFC 7231 specifies which methods are safe to retry under what conditions, and the entire web’s resilience depends on retry behaviour being assumed everywhere by default.
Webhook providers go further. Stripe’s webhook documentation explicitly warns implementers: “your endpoint should be idempotent” — because Stripe will retry across a 3-day window if any delivery fails, and your receiver will see the same event multiple times even on the happy path (Stripe Webhooks Best Practices, 2024). GitHub, Shopify, Slack, and every major SaaS webhook source publishes equivalent guidance.
The substrate is not changing. Exactly-once delivery is a known-impossible property in asynchronous distributed systems with failures — a result formalised in the 1980s and rediscovered every time a new generation of engineers tries to design around it. What you can do is build idempotent receivers and let the substrate retry as much as it wants without producing duplicate side effects.
That is the contract that worked for payments in 2017. That is the contract that worked for webhooks in 2018. That is the contract the agent ecosystem of 2026 has not yet adopted at the framework layer.
What Does the Architectural Fix Actually Look Like?
I am going to skip the comp-sci explanation of idempotency keys, because the people who need it have already seen it twenty times. I want to focus on the architectural decision that actually closes these incidents.
Treat every state-mutating tool call as a network call to an at-least-once delivery channel. That is the only assumption that is safe. The framework will retry. The webhook source will retry. The user will retry by pressing the button. Plan for it.
The fix has three layers, in order of importance.
Layer 1 — every state-mutating tool requires an idempotency key. Not optional. Not “if the upstream service supports it.” The tool’s own contract enforces it. If the agent calls create_order(...) without an idempotency key, the call fails fast at the tool boundary with a 400, before reaching the OMS. The framework’s tool-call validator catches this in development and prevents the integration from shipping in the first place.
Layer 2 — the idempotency key has a defined synthesis rule. The agent does not “generate” the key on retry. The key is derived from the inputs of the original call — a hash of the caller, the operation, and the semantically-meaningful inputs. On retry, the same inputs produce the same key. The key is stable across retries because it is derived, not invented. This rule directly addresses failure case 3 (the ghost order) — the LLM cannot accidentally regenerate a UUID if the UUID is a deterministic hash of the input.
Layer 3 — there is a deduplication store at the tool boundary. A cheap key-value store keyed by (tool, idempotency_key) returns the cached response on duplicate calls. TTL is generous — Stripe’s 24-hour window is the canonical reference, and 7 days is fine for high-cost operations like billing or order creation. Storage is cheap. A second customer charge is not.
This is not novel architecture. Stripe published the canonical pattern for it in 2017. The reason it does not exist by default in agent frameworks is that the frameworks were optimised for prototyping, not production — and the production cost of the missing layer only becomes visible after the first incident.
The deeper reason it does not exist is that the agent frameworks are converging on the wrong default. They are converging on “make tool calls easy” — which is correct for prototyping — but the production-correct default is “make tool calls safe”, which is a different property. Easy and safe are not the same. Easy means one annotation gets you a tool. Safe means one annotation gets you a tool plus the contract that ensures the tool can be retried without harm. The frameworks that ship safe-by-default tool wrapping in the next 18 months will eat the lunch of the frameworks that ship easy-by-default. This pattern repeats every time a substrate matures. It happened to RPC. It happened to REST. It will happen to agents.
What Does the Gap Actually Cost?
The gap between “should be idempotent” and “is idempotent” looks small in a design doc. In production, it costs:
- Direct revenue impact when duplicate billing requires refund + concession.
- Trust erosion when fourteen-email incidents hit social media or get tweeted at customer support.
- Engineering time when reconciliation between a ledger and an entitlement system takes a week.
- Audit surface when finance discovers that the system of record for charges and the system of record for grants disagree.
- Opportunity cost when the team spends two sprints firefighting the integration instead of building the next feature.
- Project survival when leadership concludes the agent platform is “not production-ready” and pulls the funding. This is the failure mode behind Gartner’s 40% project-cancellation forecast — not the AI being insufficiently capable, but the integration around it being insufficiently durable (Gartner, 2025).
In every post-mortem I have run on these incidents, the cost-to-fix-after is at least 10× the cost-to-design-correctly-before. The pattern is depressingly consistent.
What Do the Three Engineering Rules Look Like in 2026?
Three rules I am asking every team I work with to adopt. They are not new. They are the same rules a Stripe engineer would have given you in 2018, restated for an agent context.
Rule 1 — Tools, not agents, own idempotency. The agent is the wrong layer to enforce it. The agent is non-deterministic by design. The tool is the deterministic boundary. The contract belongs there. Every state-mutating tool exposes an idempotency_key parameter; the framework synthesises it from inputs if the agent does not supply one.
Rule 2 — Test retries explicitly. Every state-mutating tool ships with a regression test that calls it twice with the same inputs and asserts identical end state. CI catches the violation before the framework’s retry policy does. This is the single most cost-effective test you can add to an agent codebase, and almost no team I have worked with is doing it consistently.
Rule 3 — Treat idempotency as a versioned contract. When the tool’s input shape changes, the key derivation changes, and old in-flight retries should fail closed, not silently re-execute against the new shape. Most teams miss this on the first refactor and discover it on the second incident.
These three rules together cost a small engineering tax — perhaps 5% on tool development time — and prevent every one of the five failure modes documented above. The math is not subtle.
Frequently Asked Questions
Why don’t agent frameworks enforce idempotency by default?
The frameworks were optimised for prototyping speed, where retry-on-failure with no deduplication is the easiest default. Production correctness was not the original design constraint. As 51% of teams now run agents in production (LangChain, 2024), the framework defaults are misaligned with the deployment reality, and the production incidents are paying for the misalignment.
Isn’t this just a Stripe-specific problem?
No — Stripe is the most-cited reference because their 2017 idempotency engineering blog became the canonical pattern. The problem is structural to any system where at-least-once delivery meets non-idempotent operations. AWS SQS, Kafka, GitHub webhooks, Shopify webhooks, and HTTP retries all have the same shape (AWS SQS, 2024). The solution is general.
Can’t the LLM provider just add idempotency at their layer?
LLM provider idempotency only covers the model call itself, not the downstream tool calls the model triggers. The retry storms documented above happen after the model has produced the tool call — at the framework layer, the SDK layer, or the webhook layer. Idempotency must live at the tool boundary, where the side effect actually occurs.
What about exactly-once delivery?
Exactly-once delivery in asynchronous distributed systems with failures is impossible by formal proof — a result well-established since the 1980s. What is achievable is exactly-once processing, which is what an idempotency key plus deduplication store provides. The substrate stays at-least-once; the receiver makes duplicate work harmless.
How does this map to Gartner’s 40% cancellation forecast?
Gartner forecasts over 40% of agentic AI projects will be cancelled by end of 2027, citing governance, ROI, and risk-control gaps (Gartner, 2025). Production reliability is the load-bearing element under all three. An agent platform that ships duplicate charges to customers does not survive the next budget review, regardless of how strong the use case looked in the pilot.
What Is the Closing Argument?
The agent ecosystem is going through the same maturation curve every distributed-systems substrate has gone through. The 1990s had it for RPC. The 2000s had it for SOAP. The 2010s had it for REST and webhooks. Each generation rediscovered idempotency the hard way, usually after a billing incident hit the press.
The 2020s have it for agents. The good news is that we know the answer. The bad news is that the framework defaults are not yet aligned to it, and the production incidents are paying for the misalignment.
If you are building anything where an agent calls a tool that mutates state, the most useful question you can ask this quarter is: what happens if this exact call is made twice? If the answer is anything other than “the same thing happens once,” you have an incident in your future. The only variable is the timing.
Idempotency is not a clever pattern. It is a 25-year-old constraint that distributed-systems people stopped negotiating about a long time ago. The agent ecosystem is currently rediscovering why.
The fix is older than most of the engineers shipping the bug.
This article is part of a four-week series connecting old software-engineering principles to new AI failure modes. Companion piece: Postel’s Law and Why Your AI Agents Fight Each Other.