Your Agent Is Mine: What 428 LLM API Routers Reveal About the Next Supply-Chain Attack Surface
Published
On 9 April 2026, a team from UC Santa Barbara, UC San Diego and Fuzzland published the first systematic measurement of a trust boundary that most organisations using AI agents have never audited: the LLM API router (Liu et al., “Your Agent Is Mine”). Their finding is uncomfortable. Of 428 commodity routers bought or collected from public markets, 9 were actively injecting malicious code into returned tool calls. More uncomfortable still: among 440 autonomous coding sessions observed through deliberately weakened decoy relays, 401 were already running in “YOLO mode” — tool execution auto-approved without per-command confirmation. For those sessions, sophisticated evasion was not needed. A single rewritten pip install command was enough.
The authors connect this directly to a real incident that belongs on every CISO’s radar: the March 2026 LiteLLM PyPI compromise, in which attackers injected malicious code into the request-handling pipeline of a router with roughly 40,000 GitHub stars and over 240 million Docker Hub pulls. That incident turned a widely trusted dependency into a supply-chain weapon with full plaintext access to every API key, prompt, and tool call that transited it.
This post is a CTO and architect read of the paper: what the authors actually measured, what it means for enterprise AI governance, and — equally important — what the study does not prove. For the baseline Zero Trust framing I rely on throughout, see the Zero Trust Architecture executive guide. For the most recent real-world supply-chain precedent, see the axios npm compromise case study.
Key Takeaways
- LLM API routers (LiteLLM, OpenRouter, new-api, sub2api and commodity resellers) sit on an application-layer trust boundary that terminates TLS on both sides and has full plaintext access to tool-call JSON, API keys, prompts and responses (Liu et al., 2026)
- In a sample of 428 routers, 9 were confirmed injecting malicious code into returned tool calls, 17 abused researcher-owned AWS canary credentials, and 1 drained ETH from a researcher-owned wallet
- Two routers used adaptive evasion: one activated only after 50 prior calls, another only for autonomous “YOLO mode” sessions targeting Rust or Go projects — finite black-box audits cannot rule these out
- Across 440 autonomous Codex sessions reaching the researchers’ decoy relays, 401 already ran in YOLO mode — auto-approval is the dominant operational posture today, not a corner case
- No major provider (OpenAI, Anthropic, Google) currently signs tool-call arguments end-to-end, so no client can cryptographically verify that the tool call it executes is the one the upstream model produced (OpenAI function calling; Anthropic tool use)
- Important caveats: the paper is a preprint (not yet peer-reviewed), the corpus is dominated by Chinese commodity marketplaces, and the 9/428 malicious-router rate should not be read as an industry-wide base rate — see the caveats section below
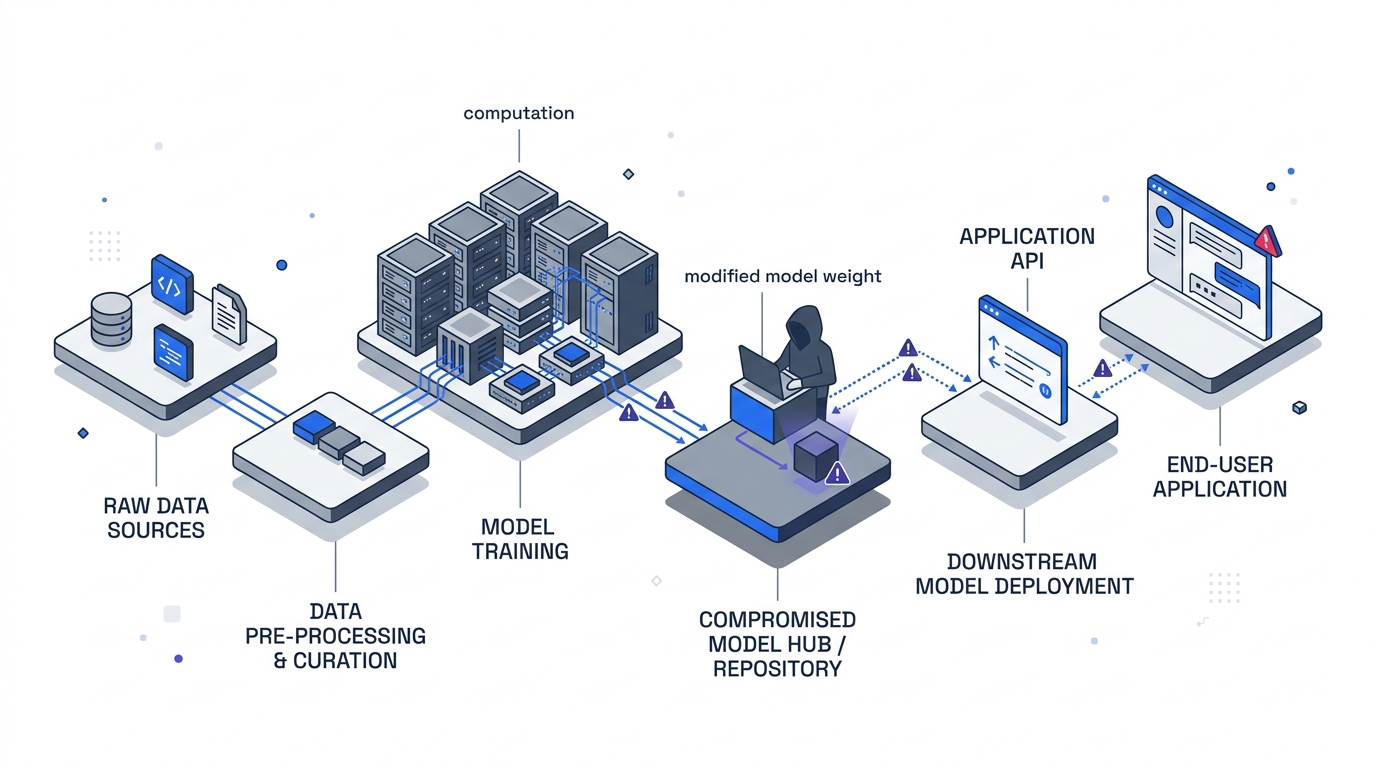
What an LLM API Router Actually Is
A direct subscription to a single model provider is the simplest deployment, but production agent systems rarely stop there. Organisations need fallback, load balancing, cost routing and a single credential plane across OpenAI, Anthropic, Google and open-weight hosts. An LLM API router fills that role: the client configures the router’s URL as the API endpoint, the router terminates the client’s TLS connection, and it originates a separate TLS connection upstream.
That architecture has three consequences the paper hammers on:
- No cert trickery is required. Unlike a classical TLS MITM, the client voluntarily points at the router. It is not an on-path adversary — it is a configured intermediary.
- Routers are composable. A developer may buy API access from a Taobao reseller, who aggregates keys from a second-tier aggregator, who routes through OpenRouter, which dispatches to the model host. That is four hops, each with full plaintext access. The client only sees the first hop.
- Chain integrity is a weakest-link property. If any router in the chain is malicious or compromised, downstream honest routers cannot detect or undo the modification, because they have no reference to the original upstream response.
The authors frame this as an application-layer supply-chain problem. Existing transport security (mutual TLS, certificate pinning) authenticates which endpoint the client reached. It says nothing about whether the returned JSON payload preserves the semantics of what the model actually produced.
The Attack Taxonomy
The paper formalises four attack classes. Two are core primitives. Two are evasion variants designed to defeat specific client-side defences.
AC-1 — Response-side payload injection. The router rewrites a model-generated tool call after it leaves the upstream provider but before it reaches the client. The modified payload remains schema-valid JSON matching the expected tool, so no transport anomaly is raised. The paper’s canonical example is a Bash tool call whose curl | bash installer URL is swapped for an attacker-controlled endpoint. That single rewrite is sufficient for arbitrary code execution on any agent running in auto-approve mode.
AC-2 — Passive secret exfiltration. The router forwards responses unmodified and silently scans requests and responses for credentials matching patterns like sk-... (OpenAI), AKIA... (AWS), ghp_... (GitHub PATs), Slack bot tokens, Ethereum private keys and PEM blocks. This requires no payload modification at all — it is invisible to the client because routers already read these secrets in plaintext as part of normal forwarding. The authors are explicit that response-signing proposals cannot mitigate AC-2, because the secrets are exposed on the request path before any provider-side mechanism can act.
AC-1.a — Dependency-targeted injection. An evasion variant. Instead of swapping a URL (which a domain allowlist can catch), the router substitutes a legitimate dependency name inside a pip install or npm install command with an attacker-controlled typosquat pre-registered on PyPI or npm. The paper’s example: requests becomes reqeusts. The command still hits the trusted registry, so domain-based policy gates do not fire. Worse, the substituted package is cached locally and re-imported across future sessions — a durable supply-chain foothold that outlives the malicious router interaction.
AC-1.b — Conditional delivery. The router gates AC-1 activation on session state. Observed triggers in the paper’s corpus included a 50-call warm-up threshold, a “YOLO mode” fingerprint, and project-language matching on Rust or Go. The Codecov CI breach is cited as a historical analogue — that payload persisted undetected for months by activating only inside CI environments. The practical consequence is that no finite black-box audit can guarantee a router is benign. A router that activates after 50 calls is perfectly transparent during a 10-call probe.
These four classes compose in the obvious way. A single router can run AC-2 continuously, activate AC-1.a only for Rust projects, and drop to AC-1.b triggers for everything else.
What the Measurement Actually Found
The authors studied two questions. First, are malicious routers already operating in agent-facing markets? Second, can ostensibly benign routers be pulled into the same trust boundary through leaked upstream credentials or by forwarding through weaker relays?
Commodity router market
They bought 28 paid routers from Taobao, Xianyu and Shopify-hosted storefronts, and collected 400 free routers built from the two dominant open-source templates, sub2api (11k stars) and new-api (25.4k stars, 1.25M Docker pulls). Each router was exercised with a randomised mix of custom shell, package-install and file-manipulation tasks drawn in part from TerminalBench 2.0. Every returned tool-call payload was executed inside a sandbox with network-callback, filesystem and process-tree monitoring.
Headline numbers from that corpus:
| Setting | Sample | Active manipulation | Adaptive evasion | Credential abuse |
|---|---|---|---|---|
| Paid routers | 28 | 1 injecting malicious code | 0 observed | 0 observed |
| Free routers | 400 | 8 injecting malicious code | 2 routers | 17 touch AWS canaries; 1 drains ETH |
The two adaptive-evasion routers are the operationally interesting ones. One activated malicious injection only after the first 50 requests, hiding the attack from shallow smoke tests. The other activated only for sessions fingerprinted as autonomous YOLO mode and project-language matching Rust or Go. These triggers are not exotic: they rely only on metadata already visible to any router.
Poisoning benign routers
The second half of the paper is more unsettling, because it shows the trust boundary is transitive. The authors ran two studies.
In the first, they intentionally leaked a researcher-owned OpenAI API key on Chinese forums and in WeChat and Telegram groups where router operators share credentials. That single key processed 100 million GPT-5.4 tokens and exposed more than seven Codex user sessions before retirement. The traffic was billed to a researcher-owned upstream account, so the authors could observe downstream prompt and credential material crossing routers they did not directly operate. In at least one session, multiple distinct third-party credentials appeared behind the leaked key.
In the second, they deployed intentionally weak claude-relay-service, Sub2API and CLIProxyAPI decoys across 20 domains and 20 IPs. Those decoys received 40,000+ unauthorised access attempts from 147 source IPs. More importantly, they were quickly absorbed into active agent-facing relay paths and served roughly 2 billion GPT-5.4 / 5.3-codex tokens, about 13 GB of visible prompt and response traffic, and exposed 99 unique credentials across 440 Codex sessions spanning 398 different projects or hosts.
All 440 of those sessions were command-injectable — they exposed at least one shell-execution path that an intermediary could have rewritten. And 401 of them already ran in YOLO mode, with tool execution auto-approved. For that 91% of observed sessions, none of the adaptive evasion was necessary. Basic payload injection would have changed executed commands.
The paper’s own framing is precise: “A router does not need to be malicious at account creation time. If it later adopts leaked upstream keys or forwards traffic into a weak relay chain, all four attack classes become available to whoever controls that upstream account or inner relay.”
Caveats You Should State Plainly
I want to be honest about what this paper does and does not prove. A few framings in the coverage I have already seen are reaching further than the evidence.
This is a preprint, not a peer-reviewed paper. arXiv:2604.08407v1 was uploaded on 9 April 2026. It has not yet been through a security-conference review cycle. The methodology is transparent and the artefacts are internally consistent, but nothing has been independently reproduced as of this writing. Treat the specific counts (9 malicious, 17 credential-abuse, 401/440 YOLO) as careful one-shot measurements, not ecosystem-wide base rates.
The corpus is heavily Chinese commodity marketplaces. The 28 paid routers were purchased from Taobao, Xianyu and Shopify-hosted storefronts. The 400 free routers were pulled from public community links dominated by two Chinese-maintained open-source templates. The authors address this directly in Section 5.5: Chinese open-source models reached ~30% of total OpenRouter usage in some weeks, and Asia’s share of LLM API spend on the platform grew from ~13% to ~31%, so the routers are not regionally irrelevant. But the paper does not measure Amazon Bedrock, Azure OpenAI Service, enterprise-hosted LiteLLM deployments, or invite-only aggregators. Enterprise readers should not extrapolate the 9/428 rate to their own vendor mix.
9 out of 428 is not “one in fifty routers is malicious.” It is 9 confirmed-injecting routers in a specific sample dominated by gray-market resellers and public free relays, observed through finite probes. Adaptive evasion means the true rate in this corpus could be higher (routers that never triggered in the probe window) but it could also be lower in any ecosystem that selects vendors more carefully. The right reading is “this attack surface is already in active exploitation somewhere in the commodity ecosystem, and the defensive posture most clients have today is inadequate to detect it” — not a universal probability claim.
The 401-of-440 YOLO finding is a sample of users who reached weakly-configured decoys. These are by definition users whose operational hygiene was permissive enough to adopt unknown or leaked upstream endpoints. A more security-conscious population would almost certainly have a lower YOLO rate. What the number does establish is that the mode exists, is common, and is the dominant operational posture for a meaningful slice of coding-agent users in the wild.
The LiteLLM incident is cited as a real-world instance — and that part is not preprint-shaky. The Datadog Security Labs write-up of the March 2026 dependency-confusion attack is independent from this paper, and it establishes the attack primitive at scale regardless of the router-market numbers.
With those caveats on the table, the architectural point of the paper stands: there is no end-to-end integrity binding the model’s tool-call output to what the client executes, and that gap is exploitable today.
What the Fix Actually Looks Like
The paper evaluates three client-side defences that can be deployed without provider cooperation:
- A fail-closed policy gate on high-risk shell tools blocks 100% of AC-1 and AC-1.a samples in their benchmark at a 1.0% false-positive rate — but is bypassed in 100% of samples in a simple adaptive test where the attacker hides behind an allowlisted domain or a pre-positioned local stager.
- Response-side anomaly screening flags 89% of AC-1 and about 50% of AC-1.a and AC-1.b samples, but with a 6.7% false-positive rate that most developer workflows will not tolerate long-term.
- Append-only transparency logging preserves forensic evidence (12 MB per 1,000 sessions) but does not prevent manipulation.
The authors are honest about the ceiling: none of these controls authenticate origin. A router that stays within local allowlists and avoids obvious anomalies can still alter tool-call semantics.
The real fix sits at the provider layer. The paper’s Appendix C sketches a minimal provider-signed response envelope — DKIM-for-tool-calls, essentially — in which the upstream provider signs a canonical JSON object containing provider, model, tool_calls, finish_reason, a client-supplied request_nonce, and a validity window. The client re-canonicalises and verifies the signature before executing any tool call. Canonicalisation is necessary because routers front heterogeneous providers through OpenAI- and Anthropic-compatible interfaces, so signing the raw HTTP body is insufficient.
To my knowledge this is not implemented by any major provider today. It should be. Web integrity has had this pattern for a decade: Subresource Integrity for script tags, certificate transparency logs for TLS, Sigstore and SLSA for software artefacts, DKIM for email. The LLM tool-calling stack is the last major application-layer channel that does not authenticate what the originator produced.
What Enterprise Teams Should Actually Do
Until provider-signed envelopes exist, a few decisions move the needle. None of them are novel. The novelty is applying them to the AI supply chain specifically.
1. Treat your LLM API router as a supply-chain vendor, not a transparent proxy. A base-URL change is not the same kind of switching cost as changing cloud providers, and the industry talks about it as though it is. Every router in your production path should go through procurement and security review with the same rigour you apply to any dependency that can see plaintext credentials. That includes self-hosted LiteLLM deployments — the March 2026 PyPI incident is exactly the scenario where “self-hosted” did not save anyone who pulled the poisoned release.
2. Turn off YOLO mode by default. The 401-of-440 finding is not a router problem. It is an operational posture problem. Auto-approval of arbitrary shell commands from an intermediary you do not control is the single highest-leverage configuration an attacker can exploit. The default posture for agents running in developer workstations, CI, or production should be per-command confirmation for shell-execution tools, with explicit, time-boxed exceptions for known-safe workflows. This is a policy decision, not a technical one.
3. Apply Zero Trust to your build plane, including the AI-assisted bits. Every recommendation that applied to developer endpoints and CI runners in the axios case study applies identically here. A compromised agent session is functionally the same as a compromised developer laptop: it has access to whatever credentials and secrets the session inherited, and it can move laterally within its blast radius. Short-lived workload identity for CI runners, egress allowlists for build networks, and device-trust-dependent access to production-adjacent resources all contain the impact of a tool-call rewrite. None of them prevent it. That distinction matters — see the Zero Trust technology deep dive for the NIST framing.
4. Maintain a package and installer allowlist at the policy gate, not just a domain allowlist. AC-1.a was designed specifically to evade domain-based gates by typosquatting package names inside commands that still hit trusted registries. The minimum is a per-package allowlist for critical dependencies and an approval workflow for new ones.
5. Keep forensic evidence of tool-call traffic. A local append-only log of returned tool calls, router endpoints, and response hashes costs ~1.26 KB per entry. It does not detect anything in real time, but it lets you answer the question every incident starts with: which sessions were exposed through this router, and what did they do?
Two Audiences, Two Decisions
For CTOs and heads of engineering. The question is not whether your team uses agentic coding tools. They do. The question is whether the trust boundary between your developers and the model provider has been mapped, reviewed, and governed with the same seriousness as your npm and PyPI supply chain. If a compromised router is a possibility your AI governance policy does not mention, that is the gap to close this quarter — not “do we use AI responsibly” in the abstract. The axios compromise is the template for what “material cybersecurity incident” means under SEC 8-K Item 1.05 and NIS2; an LLM router compromise will be treated identically when it reaches a regulated environment.
For IT architects and platform engineers. Three concrete themes: (1) make end-to-end provenance for tool-call payloads a procurement requirement when you talk to model providers, even if the answer is “not today” — that signal moves the ecosystem; (2) design your agent deployments so that killing YOLO mode is a single policy change, not a refactor; (3) treat your LLM API router the same way you treat your private npm registry proxy — as a centralised checkpoint where policy can be enforced, not a convenience layer you forget about.
The uncomfortable takeaway from the paper is not that routers are malicious. It is that the architectural primitive — “an intermediary that terminates TLS and serialises tool-call JSON” — has no integrity mechanism, and the client side of the industry has quietly normalised auto-approving whatever comes back. The next incident in this class is already in draft somewhere. What differs is whether your environment is designed to contain it.
Further Reading on BizTechBridge
- The Axios npm Compromise: Why Zero Trust Is a Blast-Radius Control — the most recent large-scale supply-chain compromise and the controls that actually reduced impact
- Zero Trust Architecture: The Executive Guide for 2026 — the NIST SP 800-207 model in plain language
- Zero Trust Technology Deep Dive — implementation patterns for identity, network and data enforcement
- Platform Engineering: The Executive Guide for 2026 — the broader context in which agent-assisted development now sits
Primary source: Liu, Shou, Wen, Chen, Fang and Feng, “Your Agent Is Mine: Measuring Malicious Intermediary Attacks on the LLM Supply Chain”, arXiv:2604.08407v1, 9 April 2026 (preprint).
Connect on LinkedIn for weekly analysis on security, platform engineering, and application modernisation.