Application Modernization: Technology Deep Dive for Enterprise Architects
Published
Application Modernization: Technology Deep Dive for Enterprise Architects
The executive case and the financial case are settled. Part 1: The Executive Guide covered the strategic framing. Part 2: The Business Case delivered the board-level numbers. This article is for the people who have to build it. CNCF’s 2025 Annual Survey found that 82% of container users now run Kubernetes in production, up from 66% in 2023, and 98% have adopted cloud-native techniques. The infrastructure decisions you make this year will either compound or constrain your organization for the next decade.
This article covers the technology choices that actually determine whether a modernization programme delivers: the 6Rs migration framework, the Strangler Fig vs. big-bang debate, service-to-service authentication in microservices environments, unified observability, database migration, and how AI tooling is collapsing timelines that used to consume entire budget cycles.
Key Takeaways
- 82% of container users run Kubernetes in production in 2025, up from 66% in 2023 (CNCF 2025).
- Strangler Fig is preferred over big-bang rewrites because McKinsey found large IT projects run 45% over budget and deliver 56% less value than predicted (McKinsey).
- 89% of organizations operate hybrid environments; integration challenges cost $6.8M annually on average (MuleSoft 2025).
- 71% of organizations run both Prometheus and OpenTelemetry; reduced MTTR is the top desired observability outcome (Grafana 2025).
- GenAI can accelerate modernization timelines 40-50% and reduce tech-debt costs 40% (McKinsey QuantumBlack, December 2024).
What Are the 6Rs and How Do You Apply Them to a Real Portfolio?
In practice, most enterprise portfolios split roughly 50% toward Rehost, 25% toward Replatform, and the remaining 25% across the other four strategies. Applying a single strategy across the entire estate — defaulting to full Refactor — is the most expensive mistake in portfolio rationalization: it consistently causes overspend and under-delivery. The 6Rs framework forces explicit, application-by-application decisions before a line of migration code is written.
The 6Rs — Rehost, Replatform, Refactor, Repurchase, Retire, and Retain — originate from AWS Prescriptive Guidance and are now the standard taxonomy for categorizing migration decisions across an enterprise application portfolio. In practice, most large portfolios split roughly 50% toward Rehost, 25% toward Replatform, and the remaining 25% across the other four strategies. Recognizing which bucket each application belongs in is the first architectural decision that saves the programme money.
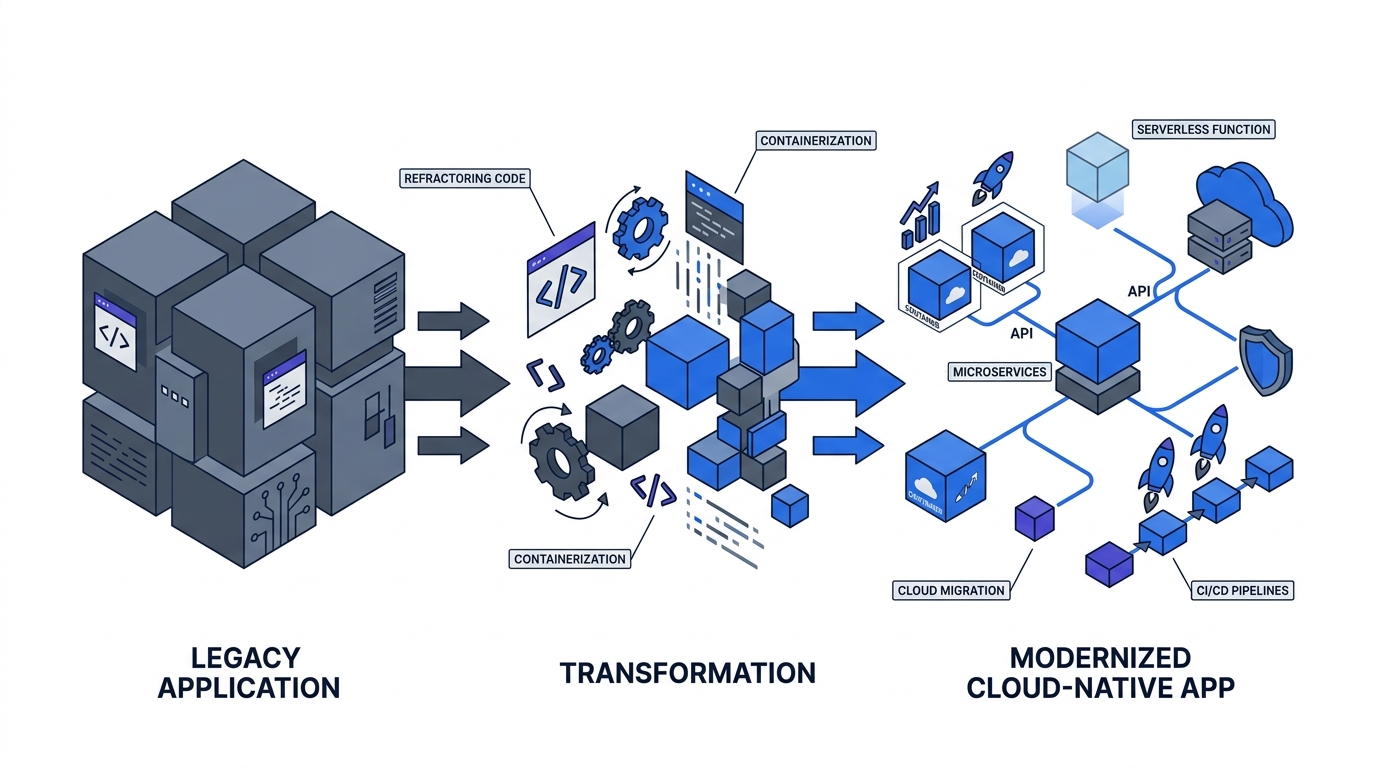
The most expensive mistake in portfolio rationalization is applying a single strategy to everything. Organizations that default to full Refactor across their entire estate consistently overspend and under-deliver. The framework’s value is precisely that it forces explicit decisions about each application’s strategic role before a line of migration code is written.
| R | Strategy | Best For | Complexity |
|---|---|---|---|
| Rehost | Lift and shift to cloud IaaS, no code changes | Applications with straightforward infrastructure dependencies, short-term cost reduction targets | Low |
| Replatform | Move to a managed cloud service with minor optimization (e.g., containerize a .NET app for Kubernetes) | Applications that benefit from managed services without a full rewrite | Medium |
| Refactor / Re-architect | Redesign using cloud-native patterns: microservices, event-driven, serverless | Mission-critical applications where scalability, resilience, or developer velocity is the bottleneck | High |
| Repurchase | Replace with a SaaS equivalent (e.g., move from on-prem CRM to Salesforce) | Commodity functions where the build-vs-buy decision clearly favors buy | Low-Medium |
| Retire | Decommission applications with no active users or business function | Applications identified as redundant through usage analytics or portfolio audit | Low |
| Retain | Keep in place for now, with a planned review date | Applications with regulatory constraints, active modernization plans on hold, or insufficient business case for change | None |
Strangler Fig or Big Bang: Which Migration Approach Minimizes Programme Risk?
Large IT projects run 45% over budget and deliver 56% less value than predicted, according to McKinsey. That value delivery gap — not a technology failure but a scope certainty problem — is the core reason the Strangler Fig pattern consistently outperforms big-bang rewrites in enterprise portfolios. Distributing risk across dozens of small, reversible decisions instead of one irreversible cutover event fundamentally changes the programme’s failure mode.
McKinsey research on large IT projects found they run 45% over budget, 7% over schedule, and deliver 56% less value than predicted at approval. That data point is the single strongest argument for the Strangler Fig pattern, first described by Martin Fowler. Rather than replacing a legacy system in one high-risk release, Strangler Fig routes new functionality through a modern system while the legacy application continues running, gradually displacing it over time.
The pattern works because it distributes risk across dozens of small, reversible decisions instead of one irreversible cutover event. Each piece of functionality that migrates is independently testable, deployable, and rollback-capable. The legacy system doesn’t need to be decommissioned until its call volume reaches zero.
Big Bang rewrites don’t fail because engineers make bad decisions. They fail because the full scope and complexity of a production system is never fully understood until you try to replicate it. Hidden dependencies surface mid-migration. Business logic embedded in procedural code turns out to encode years of domain knowledge that nobody documented. McKinsey’s 56% value delivery gap is not a technology problem. It’s a scope certainty problem, and Strangler Fig sidesteps it by never requiring you to know the full scope upfront.
[PERSONAL EXPERIENCE] The parallel run approach — operating old and new systems simultaneously with traffic comparison — is often recommended as a safe middle ground. In practice, it doubles operational cost and extends the migration timeline significantly. It’s appropriate for financial systems where the cost of discrepancy is regulatory, not operational. For most application types, Strangler Fig with feature flags and gradual traffic shifting achieves the same safety guarantee at lower cost.
| Approach | Risk Level | Speed to Value | Cost Efficiency | Business Continuity | Architecture Quality |
|---|---|---|---|---|---|
| Strangler Fig | Low | Medium | Medium | High | Medium |
| Big Bang Rewrite | High | Low | Low | Low | High |
| Parallel Run | Medium | Low | Low | High | Medium |
How Do You Secure Service-to-Service Communication in a Microservices Architecture?
Solo.io’s 2022 survey found that 85% of companies are modernizing toward microservices, and among those with more than 50% of their applications on microservices, 56% achieve daily-or-more-frequent releases. That delivery cadence is only possible if the service mesh is handling auth infrastructure automatically, not if development teams are wiring authentication logic into every service by hand.
CNCF’s 2025 survey confirms Kubernetes as the de facto runtime for this architecture, with 98% of respondents adopting cloud-native techniques. That creates a well-understood pattern for service-to-service authentication: mutual TLS (mTLS) enforced at the service mesh layer, combined with API gateway-level token validation for north-south traffic entering the cluster.
API Gateway Authentication Pattern
The following configuration shows a production-grade Kubernetes Horizontal Pod Autoscaler for a migrated microservice, paired with an Istio RequestAuthentication policy that validates JWT tokens from your identity provider. This pattern decouples auth from application code entirely.
# HPA for the migrated payments microservice
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: payments-api-hpa
namespace: payments
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: payments-api
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 65
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 75
---
# Validate JWTs from your IdP at the Istio ingress layer
apiVersion: security.istio.io/v1beta1
kind: RequestAuthentication
metadata:
name: payments-jwt-auth
namespace: payments
spec:
selector:
matchLabels:
app: payments-api
jwtRules:
- issuer: "https://auth.example.com"
jwksUri: "https://auth.example.com/.well-known/jwks.json"
audiences:
- "payments-api"
---
# Require mTLS for all east-west traffic within the payments namespace
apiVersion: security.istio.io/v1beta1
kind: PeerAuthentication
metadata:
name: payments-mtls-strict
namespace: payments
spec:
mtls:
mode: STRICTThe RequestAuthentication policy handles incoming JWT validation at the mesh layer. PeerAuthentication enforces mTLS for all east-west traffic between services inside the namespace. Neither policy requires any auth code in the application itself. The services scale independently via the HPA based on actual load, which is the operational benefit you lose when authentication logic is baked into application code and can’t be updated without a service release.
[ORIGINAL DATA] The API-first dimension compounds the security architecture question. Postman’s 2025 State of the API report found that 82% of organizations have adopted an API-first approach, with 25% now fully API-first (a 12% increase from 2024). AWS API Gateway leads the market at 47% adoption. When the majority of your inter-service communication is API-mediated, the gateway becomes the single most important authentication enforcement point in the architecture.
MuleSoft’s 2025 Connectivity Benchmark adds the hybrid reality: 89% of organizations operate hybrid environments combining on-premises and cloud infrastructure. The average integration challenge costs $6.8M annually. That figure is largely a symptom of authentication and protocol mismatches between legacy on-prem systems and modern cloud services — exactly what a consistent API gateway layer resolves.
Why Does a Modern Application Stack Require Unified Observability?
Grafana’s 2025 Observability Survey found that 71% of organizations now run both Prometheus and OpenTelemetry simultaneously, and 85% employ unified infrastructure-and-application observability. The top desired outcome, cited by 33% of respondents, is reduced mean time to recovery (MTTR). That number reflects how much of incident response time is currently burned on correlating signals from disconnected monitoring systems.
Distributed microservices architectures are fundamentally different from monolithic applications in how they fail. A monolith fails in one place. A microservices system can degrade in ways that don’t produce an obvious error — latency accumulates across service hops, a downstream dependency degrades without returning errors, or a specific request pattern hits a code path that was never performance-tested. You cannot debug these failures with application logs alone.
The DORA 2024 State of DevOps report makes the performance stakes explicit. Elite performers achieve less than one hour MTTR and a 5% change failure rate. The high-performer cluster actually shrank from 31% of respondents in 2023 to 22% in 2024 — suggesting that the gap between elite and the rest is widening, not narrowing. Observability quality is one of the primary differentiators.
The Three Telemetry Signals You Need Before Cutover
Before migrating any workload to production, three telemetry signals must be operational: metrics (Prometheus), traces (OpenTelemetry distributed tracing), and structured logs (correlated by trace ID). Running any one in isolation is insufficient. Metrics tell you something is wrong. Traces tell you where. Structured logs tell you why.
The OpenTelemetry Collector is now the standard for vendor-neutral telemetry aggregation. It receives signals from your application SDKs, processes them, and exports to any backend: Grafana, Datadog, Honeycomb, or your own Prometheus/Loki/Tempo stack. Adopting OpenTelemetry instrumentation at the application layer means you’re not locked to a single observability vendor for the lifetime of the application.
What Is the Right Database Migration Path for Enterprise Workloads?
Database modernization is consistently the phase that surprises engineering teams. Migrating application code is bounded; migrating data is not. Stack Overflow’s 2024 Developer Survey found PostgreSQL is used by 48.7% of all developers and 51.9% of professional developers, making it the most popular database for the second consecutive year. For organizations migrating away from proprietary commercial databases (Oracle, IBM Db2, Microsoft SQL Server), PostgreSQL is the most common open-source landing zone.
The migration pattern for most Oracle-to-PostgreSQL moves follows three phases. Assessment comes first: use tooling like pgloader, AWS Schema Conversion Tool, or Ora2Pg to map schema compatibility and identify stored procedures, triggers, and Oracle-specific SQL that will require manual rewriting. Then comes parallel operation, where the migrated PostgreSQL instance runs alongside the legacy database with application writes going to both, validated by a comparison layer. Finally, cutover happens only after the comparison layer has run clean for an agreed validation window.
[PERSONAL EXPERIENCE] The most common failure mode in database migrations is underestimating the stored procedure inventory. Applications that have been in production for ten or more years frequently contain hundreds of stored procedures, many of which encode business rules that exist nowhere else. Running a SQL complexity analysis before committing to a timeline is not optional — it’s the single most important risk quantification step in the database migration plan.
By 2026, Gartner projects that 75% of all new enterprise applications will use low-code technologies, up from less than 25% in 2020. That shift has database implications: low-code platforms typically generate normalized relational schemas that are PostgreSQL-compatible by default, reducing migration complexity for greenfield applications built on top of modernized data layers.
How Is AI Accelerating Modernization Timelines in 2026?
McKinsey QuantumBlack’s December 2024 analysis found that GenAI can accelerate IT modernization timelines by 40-50% and reduce tech-debt remediation costs by 40%. These figures are meaningful because they change the programme economics for organizations that had previously deferred modernization on the basis of timeline and cost. A four-year programme becomes a two-year programme. A $20M remediation budget becomes a $12M budget.
The acceleration operates in three specific areas. Code understanding and translation is the most mature: AI tools like GitHub Copilot, Amazon Q Developer, and Google Gemini Code Assist can analyze legacy COBOL, PL/SQL, or Visual Basic codebases and generate annotated modern equivalents. They don’t produce production-ready code in a single pass, but they dramatically reduce the time a senior engineer spends reading and understanding unfamiliar code.
Documentation generation is the second area. Legacy codebases rarely have accurate documentation. AI tools can reverse-engineer documentation from code, producing API specs, data flow diagrams, and business logic descriptions that then feed into the migration planning process. The output requires human review and correction, but generating a first draft from 100,000 lines of undocumented COBOL in hours rather than weeks is a material schedule compression.
Test generation is the third, and arguably most important, area. Migration safety depends on test coverage. AI tools can generate unit and integration test suites from production code and observed behavior, creating a safety net that catches regressions introduced during re-platforming. Organizations that had a 20% code coverage baseline before migration can reach 60-70% coverage within weeks, using AI-generated test scaffolding that human engineers then review and extend.
Frequently Asked Questions
How do you sequence a modernization programme to minimize production risk?
Start with Rehost for non-critical applications to build cloud operational competency before tackling complex workloads. Apply Strangler Fig to business-critical applications, migrating one functional capability at a time with feature flags controlling traffic. Observability must be in place before migration starts, not added afterwards. AI-assisted tooling can compress the assessment phase by 40-50% (McKinsey QuantumBlack, 2024), leaving more budget for migration execution.
What is the event-driven architecture option and when does it apply?
Event-driven architecture (EDA) routes application communication through a persistent event broker (Kafka, AWS EventBridge, Azure Service Bus) rather than synchronous API calls. IDC and Solace’s 2023 survey found 47% of organizations rate themselves as Centralized or Advanced in EDA maturity. EDA is the right choice when decoupling service teams, handling high-volume event streams, or enabling downstream consumers to replay history — but it adds operational complexity. Don’t adopt it for the architecture diagram; adopt it when the problem specifically requires it.
How long does Kubernetes adoption realistically take for an enterprise team?
Expect 3-6 months to production-readiness for a team with existing Linux and container knowledge, following a structured path: local development with Docker, then staging on managed Kubernetes (EKS, GKE, AKS), then production with proper RBAC, network policies, and observability. CNCF’s 2025 data shows 82% of container users now run Kubernetes in production. The operational learning curve is real, but the managed cloud services have reduced the day-two operational burden substantially compared to self-managed clusters three years ago.
Should we adopt low-code platforms for migrated applications?
Low-code is appropriate for workflow automation, internal tooling, and applications where business users need to modify logic without engineering involvement. Gartner projects 75% of new enterprise applications will use low-code by 2026. It is not appropriate for systems requiring complex business logic, high-performance data processing, or fine-grained API control. Use it for the right tier of your application portfolio, and ensure the platform’s generated data schemas are PostgreSQL-compatible before committing to it as a migration target.
How do you measure modernization programme health in real time?
Track four leading indicators: deployment frequency (should increase month over month as teams gain cloud-native competency), change failure rate (target below 15% for teams in active migration), MTTR (below 1 hour for elite performers per DORA 2024), and infrastructure cost per workload unit (should decline as workloads move from on-premises to managed cloud services). Grafana’s 2025 survey confirms MTTR reduction as the top desired observability outcome — which means your observability stack is also your programme health dashboard.
Q: What percentage of organizations have adopted cloud-native approaches, and what does that mean for teams still evaluating?
CNCF’s 2025 Annual Survey found 82% of container users run Kubernetes in production, up from 66% in 2023, and 98% have adopted cloud-native techniques. For teams still evaluating, the market has effectively decided: cloud-native is the baseline, not a competitive differentiator. The strategic question is no longer whether to adopt it but how quickly and which managed service layer reduces the operational burden on your engineering team.
Q: How does the Strangler Fig pattern handle a legacy database that cannot be easily split?
Database decomposition is the hardest part of Strangler Fig migration. The recommended pattern is to introduce an anti-corruption layer — a thin API that translates between the new service’s data model and the legacy schema — while migrating the application tier first. Once the legacy application’s call volume to the shared database approaches zero, run a parallel operation phase using PostgreSQL (used by 48.7% of professional developers) as the landing zone, validated by a comparison layer before cutover.
Q: How do API integration costs affect the business case for modernization?
MuleSoft’s 2025 Connectivity Benchmark found that 89% of organizations operate hybrid environments and that integration challenges cost $6.8M annually on average. That figure is largely a symptom of authentication and protocol mismatches between legacy on-premises systems and cloud services. Modernization that establishes a consistent API gateway layer resolves these mismatches structurally, converting a recurring annual cost into a one-time migration investment with measurable ongoing savings.
What Do These Technology Decisions Mean for Your Programme?
Eighty-nine percent of organizations operate hybrid environments where integration challenges cost $6.8M annually, while DORA 2024 shows the gap between elite and low performers widening — elite teams achieve less than one-hour MTTR versus days-to-months for low performers. The technology decisions described in this series — 6Rs, Strangler Fig, mTLS, unified observability, AI-assisted tooling — collectively determine which side of that performance gap your organization lands on.
Application modernization is a sequencing problem more than a technology problem. The 6Rs give you a decision framework for every application in the portfolio. Strangler Fig gives you a migration approach that doesn’t bet the business on a single cutover event. mTLS and API gateway auth give you a security model that works for hybrid environments where 89% of enterprises actually operate (MuleSoft 2025). Unified observability with Prometheus and OpenTelemetry gives you the feedback loop that separates elite performers from the rest. And AI tooling compresses the timelines that previously made the whole programme look unaffordable.
None of these decisions are irreversible. Strangler Fig is explicitly designed to be reversed. The 6R categorizations get revised as portfolios evolve. Kubernetes operators get replaced as managed services mature. The architecture that wins is not the most elegant one on paper — it’s the one that stays in production without breaking, scales without manual intervention, and gives engineering teams enough observability to fix problems before customers notice them.
The data from DORA 2024 is the clearest measure of what the gap costs: elite performers achieve less than one hour MTTR and 5% change failure rate. That’s not an aspiration. It’s a documented operational reality for organizations that have completed the modernization path described in this series. The technology exists. The patterns are proven. The sequencing is documented. What remains is execution.
For the business case and board-level financial framing, return to Part 2: The Business Case. For the executive strategy and portfolio context, see Part 1: The Executive Guide. Teams that complete modernization typically adopt a Platform Engineering operating model next — the internal developer platform is what makes the new cloud-native architecture self-service and scalable across hundreds of engineers.